



















- Специальный корреспондент



Представьте, что ваш Wi-Fi роутер превратится в устройство слежения. Звучит антиутопично? Но исследователи из Университета Карнеги-Меллона уверяют, что это хорошая идея для помощи пожилым людям. С помощью Wi-Fi маршрутизаторов, нейросетей и глубокого обучения они смогли создать изображения субъектов в комнате в полный рост.
 Недавнее исследование показало, что вместо привычных способов можно использовать простые Wi-Fi-маршрутизаторы. Они позволяют успешно определять позы и положение людей и четко отображать их в 3D.
Недавнее исследование показало, что вместо привычных способов можно использовать простые Wi-Fi-маршрутизаторы. Они позволяют успешно определять позы и положение людей и четко отображать их в 3D.
Привычные технологии наблюдения (камеры слежения, радарные технологии и пр.) имеют свои недостатки. У одних проблемы с конфиденциальностью (вряд ли кто-то захочет установить камеру наблюдения в своей ванной), у других космическая стоимость.
Новое исследование может стать прорывом в области здравоохранения, безопасности, игр (VR) и множества других отраслей. Wi-Fi позволит решить типичные проблемы обычных камер наблюдения: плохое освещение и препятствия (например, закрывающая обзор мебель), а также потеснит традиционные радарные датчики, LiDAR и т. д., так как новое решение получается дешевле и потребляет меньше энергии.
Однако это открытие связано с множеством потенциальных проблем с конфиденциальностью. Если технология станет популярной, за движениями и позами можно будет следить — даже сквозь стены — без предварительного уведомления или согласия.
С помощью алгоритмов искусственного интеллекта исследователям удалось создать из сигналов Wi-Fi, которые отражаются от людей, 3D-изображения.
С технической точки зрения это выглядело так: исследователи проанализировали амплитуду и фазу сигнала Wi-Fi, чтобы найти сигналы «помех» человека, а затем позволили алгоритмам искусственного интеллекта создать изображение.
Результаты исследования показывают, что модель, использующая сигналы Wi-Fi в качестве единственного входного сигнала, может оценивать позу нескольких объектов с той же производительностью, что и традиционные подходы на основе изображений.


Выше представлен набор синхронизированных изображений: слева находятся кадры с видео, а справа — каркасы, созданные ИИ для обнаружения Wi-Fi-сигналов. Он достаточно точно определяет количество людей, локаций и позы.
В
Учёные признают, что описанный выше метод обнаружения людей и их положения не лишён недостатков, и они все ещё видят некоторые очевидные ошибки в тестовых сценариях. Ниже вы можете увидеть несколько сравнительных изображений, которые показывают «неудачные случаи». Обычно они возникают из-за необычных поз или большого количества объектов, находящихся в комнате одновременно (движок оптимально распознаёт силуэты не более трёх человек).
 Некоторые очевидно неудачные изображения
Некоторые очевидно неудачные изображения
На самом деле многие факторы затрудняют решение этой задачи. Во-первых, CSI, на котором основан метод, это сложные десятичные последовательности, которые не имеют пространственного соответствия пространственному местоположению, например, как пиксели изображения.
Во-вторых, классические методы опираются на точные измерения времени пролёта и угла прихода сигнала между передатчиком и приёмником. Центр объекта определяется только этой технологией. Кроме того, точность локализации всего около 0,5 метра из-за случайного фазового сдвига, допускаемого стандарт связи IEEE 802.11n/ac, и помех, которые вызывают электронные устройства в аналогичном диапазоне частот (микроволновая печь, мобильные телефоны). Для решения этих проблем учёные обратились к недавно предложенным архитектурам глубокого обучения в компьютерном зрении и предложили архитектуру нейронной сети, которая может выполнять оценку позы по сигналам Wi-Fi. Рисунок ниже иллюстрирует, как алгоритм может оценить позу, используя только сигнал WiFi в сценариях с окклюзией и несколькими людьми.
Предстоит ещё много работы, и исследователи предполагают, что их технологию можно улучшить несколькими способами. В основном, за счёт более качественных обучающих датасетов для нейросети, оценивающей положение людей на основе Wi-Fi сигналов, особенно в разных планировках помещений.
Хотя новый метод рекламируется, как конфиденциальный способ наблюдения за безопасностью одиноких пожилых людей и является очень доступным решением для этой цели, некоторые люди наверняка будут обеспокоены потенциальной угрозой шпионажа через их Wi-Fi-маршрутизаторы.
DensePose — это технология, разработанная Meta Platforms Inc. (запрещено в России), которая создаёт трёхмерные изображения людей с помощью плоской RGB-проекции.
Для улучшения обучения сети Wi-Fi-входа, перед обучением основной сети, исследователи проводят трансферное обучение, минимизируя различия между многоуровневой картой объектов, созданной с помощью изображений, и картой, созданной сигналами Wi-Fi.
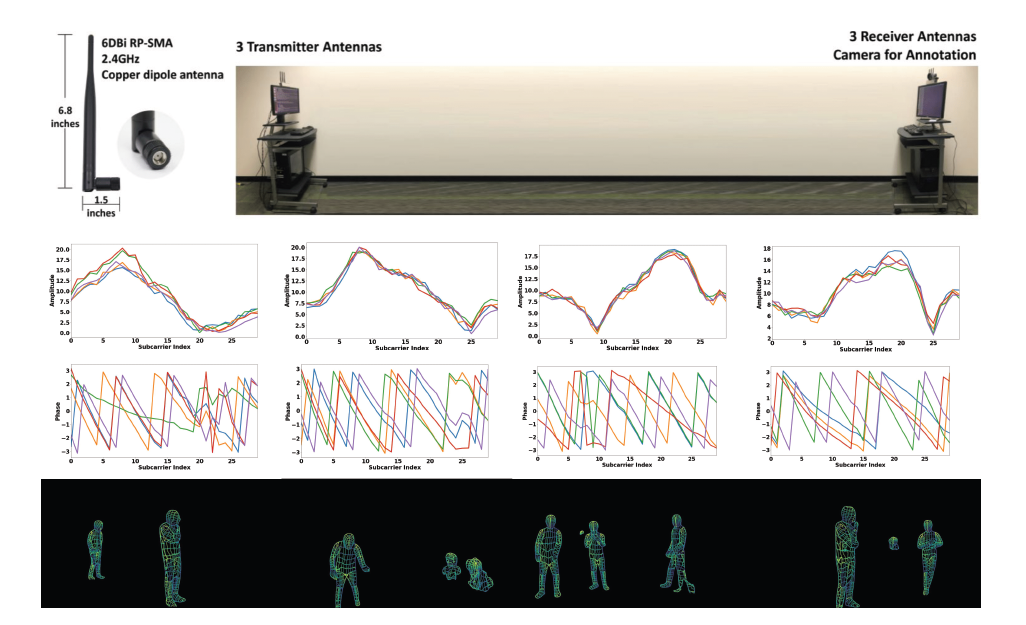
Сырые данные CSI дискретизируются с частотой 100 Гц как комплексные значения в течение 30 поднесущих частот (линейно разнесённых в диапазоне 2,4 ГГц ± 20 МГц) передающихся между 3 антеннами-источниками и 3 приёмными антеннами.
 Рисунок 2
Рисунок 2
Каждая выборка CSI содержит реальную матрицу целых чисел 3 × 3 и мнимую целочисленную матрицу 3 × 3. На входе нашей сети содержится 5 последовательных выборок CSI на 30 частотах, которые организованы в виде тензора амплитуды 150 × 3 × 3 и фазового тензора 150 × 3 × 3 соответственно. Наши сетевые выходы включают 17 × 56 × 56 тензора ключевых точек тепловых карт (по одной карте 56 × 56 для каждой из ключевых точек) и тензор UV-карт размером 25 × 112 × 112 (одна карта 112 × 112 для каждой из 24 частей тела с одной дополнительной картой для заднего вида).
 Рисунок 3
Рисунок 3
Сырые выборки CSI зашумлены случайным фазовым сдвигом и переворотом (см. Рисунок 3(b)). Большинство решений на базе Wi-Fi не учитывают фазу CSI.
В сырых выборках CSI (5 последовательных выборок, представленных на рис.3(a-b)), амплитуда (𝐴) и фаза (Φ) каждого сложного элемента 𝑧 = 𝑎 +𝑏𝑖 вычисляются по формуле
𝐴 = √︁(𝑎2 + 𝑏2) и Φ = 𝑎𝑟𝑐𝑡𝑎𝑛(𝑏/𝑎)
Обратите внимание, что диапазон функции арктангенса составляет от −𝜋 до 𝜋, и значения фазы за пределами этого диапазона переносятся, что приводит к прерыванию значений фаз. Первый шаг нашей обработки состоит в том, чтобы развернуть следующую фазу:
Δ𝜙𝑖, 𝑗 = Φ𝑖, 𝑗+1 − Φ𝑖, 𝑗
если Δ𝜙𝑖, 𝑗 > 𝜋, Φ𝑖, 𝑗+1 = Φ𝑖, 𝑗 + Δ𝜙𝑖, 𝑗 − 2𝜋
если Δ𝜙𝑖, 𝑗 < −𝜋, Φ𝑖, 𝑗+1 = Φ𝑖, 𝑗 + Δ𝜙𝑖, 𝑗 + 2𝜋,
где 𝑖 обозначает индекс измерений в пяти последовательных образцах, а 𝑗 обозначает индекс поднесущих (частот). После развертывания каждая кривая фазы переключения на рисунке 3(b) восстанавливается до непрерывных кривых на рисунке 3(c).
Обратите внимание, что среди 5 кривых фаз на рис. 3(с), снятых с 5 последовательных образцов, есть случайные колебания, которые нарушают временной порядок среди выборок. Чтобы сохранить временной порядок сигналов, используется линейная аппроксимация. Однако прямое применение линейной аппроксимации к рисунку 3(c) ещё больше усилит колебания (см. неудачный результаты на рисунке 3(d)).
На рисунке 3(с) используется медианный и равномерный фильтры, чтобы исключить выбросы как во временной, так и в частотной области, что приводит к Рисунку 3(d). В итоге получаются полностью чистые значения фазы с помощью метода линейной подгонки, по приведенным ниже уравнениям:
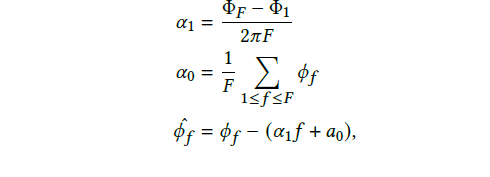
где 𝐹 обозначает наибольший индекс поднесущей (30 в нашем случае) и 𝜙ˆ𝑓 — чистые значения фазы на поднесущей 𝑓 (𝑓-я частота). На рисунке 3(f) показаны окончательные кривые фаз, согласованы во времени.
 Рис 4
Рис 4
Извлекаются скрытые пространственные объекты CSI с помощью двух энкодеров: один для тензора амплитуды, а другой для фазового тензора, где оба тензора имеют размер 150×3×3 (5 последовательных отсчетов, 30 частот, 3 излучателя и 3 приемника). Предыдущая работа по распознаванию человека с помощью Wi-Fi показывала, что сверточная нейронная сеть может быть использована для извлечения пространственных характеристик из последних двух измерений входных тензоров. Исследователи считают, что положение объектов на 3 × 3 карте не коррелируются с локациями в 2D-сцене. Это видно на рисунке 2(b). Элемент, окрашенный в синий цвет, представляет собой одномерную сводку всей сцены, захваченной излучателем 1 и приемником 3 (E1 - R3), вместо локальной пространственной информации правого верхнего угла 2D сцены. Получается, что каждый из 1350 элементов (в обоих тензорах) фиксирует уникальную одномерную сводку всей сцены.
Следуя этой идее, тензоры амплитуды и фазы сглаживаются и передаются в два отдельных многослойных персептрона (MLP), чтобы получить их положение в скрытом пространстве CSI. Учсёные объединили одномерные данные из обеих ветвей кодирования, после чего объединенный тензор передается другому MLP для выполнения слияния данных.
Следующим шагом является преобразование свойств скрытого пространства CSI в карты объектов в пространственной области. Как показано на рисунке 4, сплавленный одномерный объект преобразуется в 2D-карту объекта 24 × 24. Тогда можно извлечь пространственную информацию, применив два блока свертки и получив более сжатую карту 6 × 6.
Наконец, четыре слоя деконволюции используются для повышения дискретизации закодированной малой карты признаков до размера 3 × 720 × 1280. Устанавливаем такой размер выходного тензора, чтобы соответствовать привычному размеру для сети ввода RGB-изображений. Таким образом происходит отображение сцены, генерируемой сигналами Wi-Fi.
В частности, в RCNN WiFi-DensePose извлекают расположение в пространстве из полученной карты объектов 3 × 720 × 1280, используя ResNet-FPN. Затем выходные данные будут проходить через сеть предложений.
Чтобы лучше использовать дополнительную информацию из разных источников, следующая часть сети содержит две ветки: узел DensePose и узел ключевой точки.
Оценка местоположения ключевых точек надёжнее, чем оценка DensePose, поэтому можно обучать сеть использовать ключевые точки. Это позволит ограничивать предположения DensePose, когда они уходят слишком далеко от суставов человеческого тела. DensePose использует полностью сверточную сеть (FCN) для прогнозирования частей человеческого тела и координаты поверхности (UF-координаты) внутри каждой части, в то время как ущел ключевых точек использует FCN для оценки тепловой карты ключевых точек. Результаты объединяются, а затем передаются в блок уточнения каждой ветви, где каждый блок уточнения состоит из двух сверточных блоков, за которыми следует FCN. Сеть выводит маску ключевых точек 17 × 56 × 56 и карту IUV 25 × 112 × 112.
Следует отметить, что Сеть трансляционной модальности и WiFi-DensePose RCNN обучались совместно.

Идея состоит в том, чтобы контролировать обучение сети на основе Wi-Fi предварительно обученной сетью на основе изображений. Напрямую готовить сеть на основе Wi-Fi вместе с сетью на основе изображений не получится, потому что они получают входные данные из разных доменов.
Вместо этого исследователи сначала обучали модель DensePose-RCNN на основе изображений, быть учителем. Сеть-ученик состоит из сети трансляционной модальности и WiFi-DensePose RCNN. Обучая сеть-учитель и сеть-ученик, исследователи скармливали им синхронизированные изображения и тензоры CSI соответственно, обновляя сеть-ученика таким образом, что её основа (ResNet) имитировала характеристики сети-учителя. Цель обучения — свести к минимуму различия карт объектов, сгенерированных сетью-учеником и сетью-учителем, вычислить среднеквадратичную ошибку между картами объектов.
Потери при обучении:
𝐿𝑡𝑟 = 𝑀𝑆𝐸(𝑃2, 𝑃∗2 )+𝑀𝑆𝐸(𝑃3, 𝑃∗3 )+𝑀𝑆𝐸(𝑃4, 𝑃∗4 )+𝑀𝑆𝐸(𝑃5, 𝑃∗5 )
где 𝑀𝑆𝐸(·) вычисляет среднеквадратичную ошибку между двумя картами обхъектов, {𝑃2, 𝑃3, 𝑃4, 𝑃5} — это набор карт объектов, созданных сетью-учителем, а {𝑃∗2 , 𝑃∗3 , 𝑃∗4 , 𝑃∗5 } — набор карт объектов, созданный сетью-учеником.
Благодаря дополнительному контролю со стороны сеть-ученик получает более высокую производительность и ей требуется меньше итераций.

𝐿 = 𝐿𝑐𝑙𝑠 + 𝐿𝑏𝑜𝑥 + 𝜆𝑑𝑝𝐿𝑑𝑝 + 𝜆𝑘𝑝𝐿𝑘𝑝 + 𝜆𝑡𝑟 𝐿𝑡𝑟 ,
где 𝐿𝑐𝑙𝑠 , 𝐿𝑏𝑜𝑥, 𝐿𝑑𝑝, 𝐿𝑘𝑝, 𝐿𝑡𝑟 - это потери для классификации людей, регрессия ограничивающей рамки, DensePose, ключевые точки и перенос обучения соответственно. Потеря классификации 𝐿𝑐𝑙𝑠 и регрессия коробки потери 𝐿𝑏𝑜𝑥 — стандартные потери RCNN. Потеря DensePose 𝐿𝑑𝑝 состоит из нескольких подкомпонентов:
(1) кросс-энтропия потери для задач грубой сегментации. Каждый пиксель классифицируется как принадлежащий фону, либо одной из 24 областей человеческого тела.
(2) Перекрестная энтропийная потеря для классификации частей тела и Потеря сглаживания L1 для регрессии UV-координат. Эти потери используются для определения точных координат пикселей, т. е. 24 регрессора созданы, чтобы разбить человека на мелкие сегменты и параметризовать каждую часть с использованием локальной двумерной системы координат UV, которые идентифицируют положение UV-узлов на этой части поверхности для извлечения индивидуальных особенностей. Затем функции обрабатываются двумя узлами Keypoint и DensePose.
𝐿𝑘𝑝, необходимо, чтобы помочь DensePose балансировать между туловищем с большим количеством UV-узлов и конечностями с меньшим количеством UV-узлов. Вдохновившись Keypoint RCNN, исследователи используют каждую из 17 основных ключевых точек на тепловой карте 56 × 56, генерируя 17 × 56 × 56 ключевых точек и контролируя результат с помощью Cross-Entropy Loss. Чтобы точно упорядочить регрессию Densepose, регрессор тепловой карты ключевых точек использует те же входные функции, что и UV-карты Denspose.
В то время, как
Обнаружение людей без камер или дорогостоящих датчиков LiDAR (Light Detection and Ranging) не является чем-то новым. В 2013 году исследователи из Массачусетского технологического института нашли способ использовать сигналы мобильных телефонов для игнорирования стен, а в 2018 году другая команда Массачусетского технологического института предложила более простую версию описанной выше технологии.
Если у вас есть iPhone 12 Pro, iPad Pro 2020 года или более новые устройства, оснащенные датчиком LiDAR (он представляет собой импульсный лазерный луч и используется в основном для приложений дополненной реальности), вы можете посмотреть, как выглядит 3D-мэппинг объектов, загрузив бесплатное
Этот тип передовой технологии, которая потенциально может видеть сквозь стены, напоминает сцену из фильма
Привычные технологии наблюдения (камеры слежения, радарные технологии и пр.) имеют свои недостатки. У одних проблемы с конфиденциальностью (вряд ли кто-то захочет установить камеру наблюдения в своей ванной), у других космическая стоимость.
Новое исследование может стать прорывом в области здравоохранения, безопасности, игр (VR) и множества других отраслей. Wi-Fi позволит решить типичные проблемы обычных камер наблюдения: плохое освещение и препятствия (например, закрывающая обзор мебель), а также потеснит традиционные радарные датчики, LiDAR и т. д., так как новое решение получается дешевле и потребляет меньше энергии.
Однако это открытие связано с множеством потенциальных проблем с конфиденциальностью. Если технология станет популярной, за движениями и позами можно будет следить — даже сквозь стены — без предварительного уведомления или согласия.
Восприятие людей через WiFi-антенну, обход препятствий
Исследователи использовали три антенны Wi-Fi с маршрутизатора
Для просмотра ссылки необходимо нажать
Вход или Регистрация
стоимостью 50 долларов. Оборудование расположили в комнате с людьми, после чего успешно получили каркасную визуализацию тех, кто находился внутри.С помощью алгоритмов искусственного интеллекта исследователям удалось создать из сигналов Wi-Fi, которые отражаются от людей, 3D-изображения.
С технической точки зрения это выглядело так: исследователи проанализировали амплитуду и фазу сигнала Wi-Fi, чтобы найти сигналы «помех» человека, а затем позволили алгоритмам искусственного интеллекта создать изображение.
Результаты исследования показывают, что модель, использующая сигналы Wi-Fi в качестве единственного входного сигнала, может оценивать позу нескольких объектов с той же производительностью, что и традиционные подходы на основе изображений.
Выше представлен набор синхронизированных изображений: слева находятся кадры с видео, а справа — каркасы, созданные ИИ для обнаружения Wi-Fi-сигналов. Он достаточно точно определяет количество людей, локаций и позы.
В
Для просмотра ссылки необходимо нажать
Вход или Регистрация
, опубликованной исследователями Карнеги-Меллона, содержится подробная информация о том, как это делается. Ниже мы приводим перевод метода, но, если говорить коротко, то продемонстрированная технология основана на информации о состоянии канала сигнала Wi-Fi (CSI), которая представляет собой соотношение между волной передаваемого сигнала и волной принятого сигнала. Эти данные обрабатываются с использованием архитектуры нейронной сети с компьютерным зрением, которая может выполнять оценку позы. Чтобы упростить и, таким образом, ускорить создание каркасной визуализации человека, исследователи условно разбили человеческую фигуру на 24 сегмента.Учёные признают, что описанный выше метод обнаружения людей и их положения не лишён недостатков, и они все ещё видят некоторые очевидные ошибки в тестовых сценариях. Ниже вы можете увидеть несколько сравнительных изображений, которые показывают «неудачные случаи». Обычно они возникают из-за необычных поз или большого количества объектов, находящихся в комнате одновременно (движок оптимально распознаёт силуэты не более трёх человек).
На самом деле многие факторы затрудняют решение этой задачи. Во-первых, CSI, на котором основан метод, это сложные десятичные последовательности, которые не имеют пространственного соответствия пространственному местоположению, например, как пиксели изображения.
Во-вторых, классические методы опираются на точные измерения времени пролёта и угла прихода сигнала между передатчиком и приёмником. Центр объекта определяется только этой технологией. Кроме того, точность локализации всего около 0,5 метра из-за случайного фазового сдвига, допускаемого стандарт связи IEEE 802.11n/ac, и помех, которые вызывают электронные устройства в аналогичном диапазоне частот (микроволновая печь, мобильные телефоны). Для решения этих проблем учёные обратились к недавно предложенным архитектурам глубокого обучения в компьютерном зрении и предложили архитектуру нейронной сети, которая может выполнять оценку позы по сигналам Wi-Fi. Рисунок ниже иллюстрирует, как алгоритм может оценить позу, используя только сигнал WiFi в сценариях с окклюзией и несколькими людьми.
Предстоит ещё много работы, и исследователи предполагают, что их технологию можно улучшить несколькими способами. В основном, за счёт более качественных обучающих датасетов для нейросети, оценивающей положение людей на основе Wi-Fi сигналов, особенно в разных планировках помещений.
Хотя новый метод рекламируется, как конфиденциальный способ наблюдения за безопасностью одиноких пожилых людей и является очень доступным решением для этой цели, некоторые люди наверняка будут обеспокоены потенциальной угрозой шпионажа через их Wi-Fi-маршрутизаторы.
Методика
Новый подход позволяет получить UV-координаты поверхности человеческого тела из сигналов Wi-Fi с использованием трёх компонентов. Сначала сырые CSI сигналы проходят через амплитудную и фазовую очистку. Затем сеть кодер-декодер с двумя ответвлениями выполняет преобразование домена от очищенных образцов CSI до 2D-карт объектов, которые напоминают изображения. Затем 2D-объекты передаются в модифицированную архитектуру DensePose-RCNN для оценки UV-карты, представления плотного соответствия между 2D и 3D людьми.DensePose — это технология, разработанная Meta Platforms Inc. (запрещено в России), которая создаёт трёхмерные изображения людей с помощью плоской RGB-проекции.
Для улучшения обучения сети Wi-Fi-входа, перед обучением основной сети, исследователи проводят трансферное обучение, минимизируя различия между многоуровневой картой объектов, созданной с помощью изображений, и картой, созданной сигналами Wi-Fi.
Сырые данные CSI дискретизируются с частотой 100 Гц как комплексные значения в течение 30 поднесущих частот (линейно разнесённых в диапазоне 2,4 ГГц ± 20 МГц) передающихся между 3 антеннами-источниками и 3 приёмными антеннами.
Каждая выборка CSI содержит реальную матрицу целых чисел 3 × 3 и мнимую целочисленную матрицу 3 × 3. На входе нашей сети содержится 5 последовательных выборок CSI на 30 частотах, которые организованы в виде тензора амплитуды 150 × 3 × 3 и фазового тензора 150 × 3 × 3 соответственно. Наши сетевые выходы включают 17 × 56 × 56 тензора ключевых точек тепловых карт (по одной карте 56 × 56 для каждой из ключевых точек) и тензор UV-карт размером 25 × 112 × 112 (одна карта 112 × 112 для каждой из 24 частей тела с одной дополнительной картой для заднего вида).
Сырые выборки CSI зашумлены случайным фазовым сдвигом и переворотом (см. Рисунок 3(b)). Большинство решений на базе Wi-Fi не учитывают фазу CSI.
В сырых выборках CSI (5 последовательных выборок, представленных на рис.3(a-b)), амплитуда (𝐴) и фаза (Φ) каждого сложного элемента 𝑧 = 𝑎 +𝑏𝑖 вычисляются по формуле
𝐴 = √︁(𝑎2 + 𝑏2) и Φ = 𝑎𝑟𝑐𝑡𝑎𝑛(𝑏/𝑎)
Обратите внимание, что диапазон функции арктангенса составляет от −𝜋 до 𝜋, и значения фазы за пределами этого диапазона переносятся, что приводит к прерыванию значений фаз. Первый шаг нашей обработки состоит в том, чтобы развернуть следующую фазу:
Δ𝜙𝑖, 𝑗 = Φ𝑖, 𝑗+1 − Φ𝑖, 𝑗
если Δ𝜙𝑖, 𝑗 > 𝜋, Φ𝑖, 𝑗+1 = Φ𝑖, 𝑗 + Δ𝜙𝑖, 𝑗 − 2𝜋
если Δ𝜙𝑖, 𝑗 < −𝜋, Φ𝑖, 𝑗+1 = Φ𝑖, 𝑗 + Δ𝜙𝑖, 𝑗 + 2𝜋,
где 𝑖 обозначает индекс измерений в пяти последовательных образцах, а 𝑗 обозначает индекс поднесущих (частот). После развертывания каждая кривая фазы переключения на рисунке 3(b) восстанавливается до непрерывных кривых на рисунке 3(c).
Обратите внимание, что среди 5 кривых фаз на рис. 3(с), снятых с 5 последовательных образцов, есть случайные колебания, которые нарушают временной порядок среди выборок. Чтобы сохранить временной порядок сигналов, используется линейная аппроксимация. Однако прямое применение линейной аппроксимации к рисунку 3(c) ещё больше усилит колебания (см. неудачный результаты на рисунке 3(d)).
На рисунке 3(с) используется медианный и равномерный фильтры, чтобы исключить выбросы как во временной, так и в частотной области, что приводит к Рисунку 3(d). В итоге получаются полностью чистые значения фазы с помощью метода линейной подгонки, по приведенным ниже уравнениям:
где 𝐹 обозначает наибольший индекс поднесущей (30 в нашем случае) и 𝜙ˆ𝑓 — чистые значения фазы на поднесущей 𝑓 (𝑓-я частота). На рисунке 3(f) показаны окончательные кривые фаз, согласованы во времени.
Сеть трансляционной модальности
Для оценки UF-карт в пространственной области из сигналов 1D CSI сначала преобразуются сетевые входы из домена CSI в пространственный домен. Это делается с помощью Сети трансляционной модальности.
Извлекаются скрытые пространственные объекты CSI с помощью двух энкодеров: один для тензора амплитуды, а другой для фазового тензора, где оба тензора имеют размер 150×3×3 (5 последовательных отсчетов, 30 частот, 3 излучателя и 3 приемника). Предыдущая работа по распознаванию человека с помощью Wi-Fi показывала, что сверточная нейронная сеть может быть использована для извлечения пространственных характеристик из последних двух измерений входных тензоров. Исследователи считают, что положение объектов на 3 × 3 карте не коррелируются с локациями в 2D-сцене. Это видно на рисунке 2(b). Элемент, окрашенный в синий цвет, представляет собой одномерную сводку всей сцены, захваченной излучателем 1 и приемником 3 (E1 - R3), вместо локальной пространственной информации правого верхнего угла 2D сцены. Получается, что каждый из 1350 элементов (в обоих тензорах) фиксирует уникальную одномерную сводку всей сцены.
Следуя этой идее, тензоры амплитуды и фазы сглаживаются и передаются в два отдельных многослойных персептрона (MLP), чтобы получить их положение в скрытом пространстве CSI. Учсёные объединили одномерные данные из обеих ветвей кодирования, после чего объединенный тензор передается другому MLP для выполнения слияния данных.
Следующим шагом является преобразование свойств скрытого пространства CSI в карты объектов в пространственной области. Как показано на рисунке 4, сплавленный одномерный объект преобразуется в 2D-карту объекта 24 × 24. Тогда можно извлечь пространственную информацию, применив два блока свертки и получив более сжатую карту 6 × 6.
Наконец, четыре слоя деконволюции используются для повышения дискретизации закодированной малой карты признаков до размера 3 × 720 × 1280. Устанавливаем такой размер выходного тензора, чтобы соответствовать привычному размеру для сети ввода RGB-изображений. Таким образом происходит отображение сцены, генерируемой сигналами Wi-Fi.
WiFi-DensePose RCNN
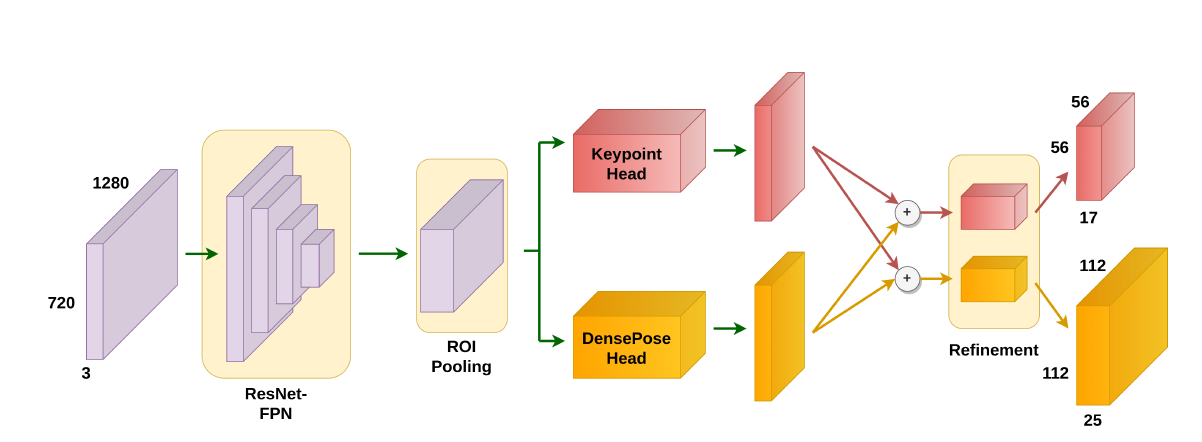
После получения представления сцены формата 3×720×1280, можно применять методы на основе изображений для прогнозирования UF-карты человеческих тел. Современные алгоритмы оценки позы двухступенчатые; сначала они запускают независимый детектор людей, чтобы определить рамку-ограничитель, а затем проводят оценку позы, исходя из изученных изображений людей. Однако каждый элемент в входных тензорах CSI является сводкой всей сцены. Невозможно извлечь сигналы, соответствующие одному человеку, из целой группы людей. Поэтому исследователи решили использовать сетевую структуру, аналогичную DensePose-RCNN, так как она может предсказать расположение отдельных людей в плотной группе.
В частности, в RCNN WiFi-DensePose извлекают расположение в пространстве из полученной карты объектов 3 × 720 × 1280, используя ResNet-FPN. Затем выходные данные будут проходить через сеть предложений.
Чтобы лучше использовать дополнительную информацию из разных источников, следующая часть сети содержит две ветки: узел DensePose и узел ключевой точки.
Оценка местоположения ключевых точек надёжнее, чем оценка DensePose, поэтому можно обучать сеть использовать ключевые точки. Это позволит ограничивать предположения DensePose, когда они уходят слишком далеко от суставов человеческого тела. DensePose использует полностью сверточную сеть (FCN) для прогнозирования частей человеческого тела и координаты поверхности (UF-координаты) внутри каждой части, в то время как ущел ключевых точек использует FCN для оценки тепловой карты ключевых точек. Результаты объединяются, а затем передаются в блок уточнения каждой ветви, где каждый блок уточнения состоит из двух сверточных блоков, за которыми следует FCN. Сеть выводит маску ключевых точек 17 × 56 × 56 и карту IUV 25 × 112 × 112.
Следует отметить, что Сеть трансляционной модальности и WiFi-DensePose RCNN обучались совместно.
Трансферное обучение
Обучение Сети трансляционной модальности и Сети RCNN WiFi-DensePose избегать случайной инициализации заняло много времени (примерно 80 часов). Для повышения эффективности обучения исследователи перенесли его из сети DensPose в сеть на основе Wi-Fi.
Идея состоит в том, чтобы контролировать обучение сети на основе Wi-Fi предварительно обученной сетью на основе изображений. Напрямую готовить сеть на основе Wi-Fi вместе с сетью на основе изображений не получится, потому что они получают входные данные из разных доменов.
Вместо этого исследователи сначала обучали модель DensePose-RCNN на основе изображений, быть учителем. Сеть-ученик состоит из сети трансляционной модальности и WiFi-DensePose RCNN. Обучая сеть-учитель и сеть-ученик, исследователи скармливали им синхронизированные изображения и тензоры CSI соответственно, обновляя сеть-ученика таким образом, что её основа (ResNet) имитировала характеристики сети-учителя. Цель обучения — свести к минимуму различия карт объектов, сгенерированных сетью-учеником и сетью-учителем, вычислить среднеквадратичную ошибку между картами объектов.
Потери при обучении:
𝐿𝑡𝑟 = 𝑀𝑆𝐸(𝑃2, 𝑃∗2 )+𝑀𝑆𝐸(𝑃3, 𝑃∗3 )+𝑀𝑆𝐸(𝑃4, 𝑃∗4 )+𝑀𝑆𝐸(𝑃5, 𝑃∗5 )
где 𝑀𝑆𝐸(·) вычисляет среднеквадратичную ошибку между двумя картами обхъектов, {𝑃2, 𝑃3, 𝑃4, 𝑃5} — это набор карт объектов, созданных сетью-учителем, а {𝑃∗2 , 𝑃∗3 , 𝑃∗4 , 𝑃∗5 } — набор карт объектов, созданный сетью-учеником.
Благодаря дополнительному контролю со стороны сеть-ученик получает более высокую производительность и ей требуется меньше итераций.
Потери
Общие потери данного подхода вычисляются как:𝐿 = 𝐿𝑐𝑙𝑠 + 𝐿𝑏𝑜𝑥 + 𝜆𝑑𝑝𝐿𝑑𝑝 + 𝜆𝑘𝑝𝐿𝑘𝑝 + 𝜆𝑡𝑟 𝐿𝑡𝑟 ,
где 𝐿𝑐𝑙𝑠 , 𝐿𝑏𝑜𝑥, 𝐿𝑑𝑝, 𝐿𝑘𝑝, 𝐿𝑡𝑟 - это потери для классификации людей, регрессия ограничивающей рамки, DensePose, ключевые точки и перенос обучения соответственно. Потеря классификации 𝐿𝑐𝑙𝑠 и регрессия коробки потери 𝐿𝑏𝑜𝑥 — стандартные потери RCNN. Потеря DensePose 𝐿𝑑𝑝 состоит из нескольких подкомпонентов:
(1) кросс-энтропия потери для задач грубой сегментации. Каждый пиксель классифицируется как принадлежащий фону, либо одной из 24 областей человеческого тела.
(2) Перекрестная энтропийная потеря для классификации частей тела и Потеря сглаживания L1 для регрессии UV-координат. Эти потери используются для определения точных координат пикселей, т. е. 24 регрессора созданы, чтобы разбить человека на мелкие сегменты и параметризовать каждую часть с использованием локальной двумерной системы координат UV, которые идентифицируют положение UV-узлов на этой части поверхности для извлечения индивидуальных особенностей. Затем функции обрабатываются двумя узлами Keypoint и DensePose.
𝐿𝑘𝑝, необходимо, чтобы помочь DensePose балансировать между туловищем с большим количеством UV-узлов и конечностями с меньшим количеством UV-узлов. Вдохновившись Keypoint RCNN, исследователи используют каждую из 17 основных ключевых точек на тепловой карте 56 × 56, генерируя 17 × 56 × 56 ключевых точек и контролируя результат с помощью Cross-Entropy Loss. Чтобы точно упорядочить регрессию Densepose, регрессор тепловой карты ключевых точек использует те же входные функции, что и UV-карты Denspose.
Потенциальная проблема с конфиденциальностью
Хотя исследователи заявили, что эту технологию можно использовать во благо, например, для наблюдения за одинокими пожилыми людей, которые нуждаются в присмотре, существуют серьёзные проблемы с конфиденциальностью, которые могут возникнуть, если технология станет массовой.В то время, как
Для просмотра ссылки необходимо нажать
Вход или Регистрация
,
Для просмотра ссылки необходимо нажать
Вход или Регистрация
, дроны и
Для просмотра ссылки необходимо нажать
Вход или Регистрация
, которые можно взломать, каждый день ставят под угрозу нашу конфиденциальность и безопасность, технология Wi-Fi-обнаружения выглядит вишенкой на торте. Ей могут злоупотреблять все, в том числе и киберпреступники. В конечном итоге люди могут потерять доверие к своим Wi-Fi маршрутизаторам.Обнаружение людей без камер или дорогостоящих датчиков LiDAR (Light Detection and Ranging) не является чем-то новым. В 2013 году исследователи из Массачусетского технологического института нашли способ использовать сигналы мобильных телефонов для игнорирования стен, а в 2018 году другая команда Массачусетского технологического института предложила более простую версию описанной выше технологии.
Если у вас есть iPhone 12 Pro, iPad Pro 2020 года или более новые устройства, оснащенные датчиком LiDAR (он представляет собой импульсный лазерный луч и используется в основном для приложений дополненной реальности), вы можете посмотреть, как выглядит 3D-мэппинг объектов, загрузив бесплатное
Для просмотра ссылки необходимо нажать
Вход или Регистрация
из магазина приложений.Этот тип передовой технологии, которая потенциально может видеть сквозь стены, напоминает сцену из фильма
Для просмотра ссылки необходимо нажать
Вход или Регистрация
Вполне возможно, что однажды она заменит камеры и другие датчики, став частью
Для просмотра ссылки необходимо нажать
Вход или Регистрация
, в которых мы скоро будем жить.
Для просмотра ссылки необходимо нажать
Вход или Регистрация