

















Lisss
Интересующийся
Копипаст с соседнего борда
Все давно привыкли искать информацию в интернете с помощью поисковых систем. И в то время как обычный человек ищет ничем не примечательный контент, хакеры давно научились использовать поисковые системы в своих целях. Сегодня я раскажу вам о параметрах поиска google с помощь которого Вы можете найти гораздо больше информации скрытой от посторонних глаз но проиндексированой поисковой системой Google.

Текст громоздкий, поэтому загнал под спойлер
Все давно привыкли искать информацию в интернете с помощью поисковых систем. И в то время как обычный человек ищет ничем не примечательный контент, хакеры давно научились использовать поисковые системы в своих целях. Сегодня я раскажу вам о параметрах поиска google с помощь которого Вы можете найти гораздо больше информации скрытой от посторонних глаз но проиндексированой поисковой системой Google.
Текст громоздкий, поэтому загнал под спойлер
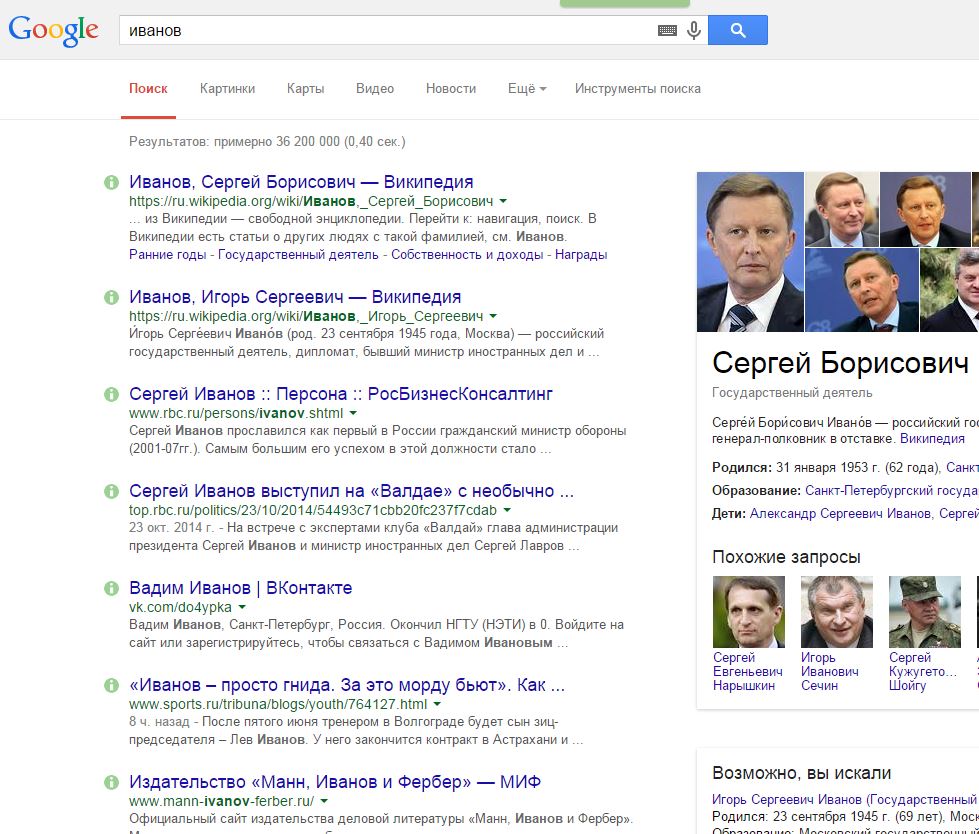
Итак рассмотрим результат поискового запроса «иванов»
Теперь, мы немного изменим наш запрос, конкретизируя область поиска. Это будет выглядеть так:
Почему так изменился поиск? Все очень просто. Мы воспользовались атрибутом allintext:, который означает «все документы, содержащие данное выражение» и атрибутом site:, означающим «все сайты из данного поддомена». Таким образом мы нашли все документы из поддомена .gov.ru, содержащие слово «иванов», причем Google не надо указывать, что ведется поиск по любому написанию этого слова и в наш поиск попадут документы, содержащие слово «ивановский», «Иванов», «Ивановский», «Иванова» и многое другое. Учитывая же, что поддомен .gov.ru является собранием официальных государственных сайтов, то мы получили ссылки на все государственные сайты, содержащие документы с упоминанием этих слов в своем тексте. Если же мы Применим следующий поиск:»allintext:»Сергей Семёнович Собянин» site:.gov.ru», то мы получим все упоминания данной личности во всех возможных государственных документах, которые попали в сферу писка Google.
Какие же атрибуты поиска содержит Google? Приведем таблицу:
Поисковый запрос
Результат
nokia phone Все, что содержит nokia и phone
распродажа OR notebook Все, что содержит слово распродажа или слово notebook
«коленчатый вал» Все, что содержит словосочетание коленчатый вал
printer -cartridge Содержащее слово принтер printer без слова cartridge
Toy Story +2 Все ссылки, содержащие название мульфильма Toy Story 2
~машина Все ссылки с упоминанием слова машина или его синонимов
define:мойка Все сведения со словом мойка (в том числе и река)
Квартиры и комнаты * Москв Выдаст ссылки на квартиры и комнаты с упоминанием словаМосква
+ Сложение. На запрос 978+456, выдаст ответ 978 + 456 = 1434
– Вычитание. На запрос 978-456, выдаст 978 — 456 = 522, но, кроме этого вы получите еще и ссылки на все документы, содержащие 978-456
* Умножение. На запрос 978*456, выдаст 978 * 456 = 445968
/ Деление. На запрос 978/456, выдаст 978 / 456 = 2.14473684, но, кроме того еще и упоминание вместе этих цифр.
% of (% от) Процент. На запрос 50% of 200 hz (или 50% от 200 hz) , выдаст 50% of (200 hertz) = 100 hertz (50 % от (200 Гц) = 100 Герц)
^ Возведение в степень. На запрос 4^18, выдаст 4^18 = 68719476736
old in new (преобразование) 45 celsius in Fahrenheit (45 цельсия в фаренгейте) дает45 градусов Цельсия = 113 градусов Фаренгейта
site:(поиск только на сайте) Запрос: site:mts.ru «SMS и MMS-MAXI» выдаст все, что есть по этому тарифу во всех регионах
link:(ссылка) Этот оператор позволяет увидеть все страницы, которые ссылаются на страницу, по которой сделан запрос.
#…#(поиск в интервале) Например: жесткий диск внешний 800 руб…5000 рубвыдаст вам все варианты по цене от 800 до 5000 рублей
info: (запрос информации о странице) Пример: info:
related: (похожие страницы) Пример: related:
cache: (просмотр сохраненных страниц) Выдает сохраненные в кеше Google страницы сайтов
filetype:(с указанием конкретного вида типов файлов)
ext:(расширение файла) Пример: кролики filetype:ppt дает ссылку на презентации Power Point на тему «кролики»
allintitle: (ищет слова в заголовках страниц)
allinurl:отыщет заданное в теле самих ссылок
allianchor:в тексте, снабженном тегом
Например, предыдущая задачка. Пишем простой гуглодорк «intitle:”Struts Problem Report”» и получаем «158,000 results». Конечно, гугл здесь хвастается и по факту отдельных хостов около 400, но все равно это не меняет дела — мы можем почти на 100% быть уверены, что там есть RCE, так как включен development mode.
Теперь давай посмотрим с другой стороны. Вот проводим мы пентест какого-то ресурса. Погуглодоркать нужно? Нужно. И собрать информацию нужно. Но делать это через браузер — совсем не наш метод. Нам нужна автоматизация процесса.
Варианта здесь, на самом деле, два. Первый — взять тулзу, которая эмулировала бы пользовательские запросы в гугл и парсила бы ответы. Минус здесь в том, что гугл не любит ботов и блочит их (капчу надо вводить). Но, используя большое количество прокси или отвечая на капчу «китайским методом» (то есть вручную), мы можем слить инфу с гугла. Второй — воспользоваться API гугла. Есть у него такая фича — Custom Search Engine, к которой можно получить доступ через специальный API. Здесь как раз автоматически можно получать инфу без проблем (капчи). Но есть другое ограничение — разрешено делать не более 100 запросов в день. Больше — платно (1000 запросов — 5 долларов, для примера). И вроде бы больше 100 ответов не получить. В зависимости от типа задачи (глубина или покрытие) можно выбрать один из вариантов соответственно.
Но для пентестерских задач могу порекомендовать такую тулзу, как
Она проста в использовании, написана на C# и работает только под win, может работать как напрямую с гуглом, так и через API. В ней нативно представлена большая база различных гуглодорков (оооочень большая), а также имеется удобная возможность сортировки и выгрузки результатов в различные форматы. То есть то, что нужно") . Итак, немного пробегусь по интерфейсу.
. Итак, немного пробегусь по интерфейсу.
Queries — как раз набор различных гуглодорков. Все разгруппировано и вполне понятно. Ставим галки где нужно, и он ищет по ним.
Далее Settings. Можно выбрать методы получения инфы. Если галка Disable scraper не стоит, то данные будут получаться эмуляцией гугления (не через API). Для этого метода рекомендую сразу добавить перечень proxy в соответствующей вкладке, а то слишком быстро заблочат. Если стоит галка, то используется API Googl’а. Немного подробнее об этом.
Для того чтобы получить доступ к этому функционалу, тебе нужны Google Custom Search ID и API key.
1. Заходим на
Главное для нас здесь две вещи. Во-первых, в настройках движка установить для поля Sites to search значение Search the entire web but emphasize included sites. Так гугл будет искать по всем сайтам, а не только по нашим (потому и все равно введенное нами имя). Во-вторых, берем значение
из Search Engine ID — это, как ты понял, идентификатор нашего кастомного поисковика. То есть полдела сделано.
2. Заходим на
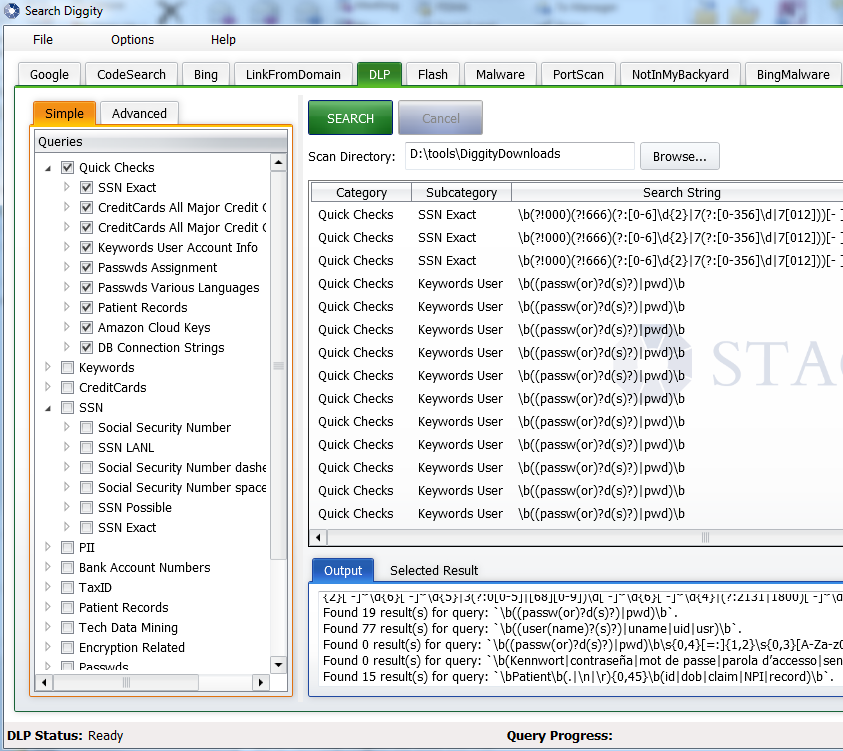
Все, теперь можно ввести оба этих значения в настройках SearchDiggity.
Следующий важный пункт — Sites, Domains, IP ranges. В нем как раз очень просто ограничить поиск для гуглодорканья. По сути, используется параметр site: от гугла. Так что можно сразу указать набор доменов, где хочешь совершать поиск, — очень удобно.
Последнее — Query appender, позволяет нам задать дополнительные строки при поиске, то есть прямо в него можно пихать гуглодорки.
Вот, в общем-то, и все. Получается очень удобно. Еще хотелось бы отметить две фичи. Первая состоит в том, что в настройках можно увеличить количество значений в ответе на запрос (Options-Settings-Google) до 100. И вторая — можно отредактировать файл в поле Default Query Definition. В нем хранится база гуглодорков. Так что можно сделать свой личный набор и оперативно использовать его впоследствии.
ФИЛЬТРУЕМ ВЫДАЧУ
По умолчанию слова и вообще любые введенные символы Google ищет по всем файлам на проиндексированных страницах. Ограничить область поиска можно по домену верхнего уровня, конкретному сайту или по месту расположения искомой последовательности в самих файлах. Для первых двух вариантов используется оператор site, после которого вводится имя домена или выбранного сайта. В третьем случае целый набор операторов позволяет искать информацию в служебных полях и метаданных. Например, allinurl отыщет заданное в теле самих ссылок, allinanchor — в тексте, снабженном тегом
1
<a name>
allintitle — в заголовках страниц, allintext — в теле страниц.
Для каждого оператора есть облегченная версия с более коротким названием (без приставки all). Разница в том, что allinurl отыщет ссылки со всеми словами, а inurl — только с первым из них. Второе и последующие слова из запроса могут встречаться на веб-страницах где угодно. Оператор inurl тоже имеет отличия от другого схожего по смыслу — site. Первый также позволяет находить любую последовательность символов в ссылке на искомый документ (например, /cgi-bin/), что широко используется для поиска компонентов с известными уязвимостями.
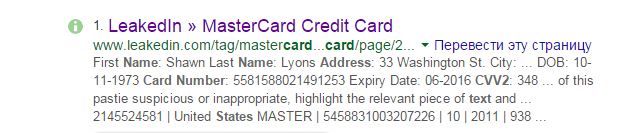
Попробуем на практике. Берем фильтр allintext и делаем так, чтобы запрос выдал список номеров и проверочных кодов кредиток, срок действия которых истечет только через два года (или когда их владельцам надоест кормить всех подряд).
allintext: card number expiration date /2017 cvv
intext: name adress state zip card number cvv2
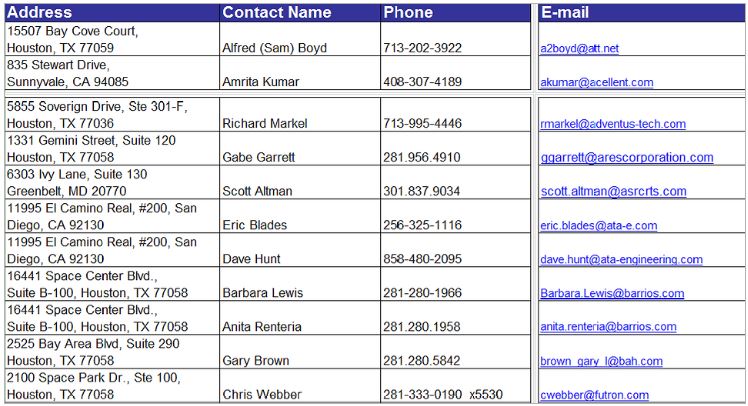
Когда читаешь в новостях, что юный хакер «взломал серверы » Пентагона или NASA, украв секретные сведения, то в большинстве случаев речь идет именно о такой элементарной технике использования Google. Предположим, нас интересует список сотрудников NASA и их контактные данные. Наверняка такой перечень есть в электронном виде. Для удобства или по недосмотру он может лежать и на самом сайте организации. Логично, что в этом случае на него не будет ссылок, поскольку предназначен он для внутреннего использования. Какие слова могут быть в таком файле?
Как минимум — поле «адрес». Проверить все эти предположения проще простого.
Пишем
inurl:nasa.gov filetype:xlsx “address”
и получаем ссылки на файлы со списками сотрудников.
ПОЛЬЗУЕМСЯ БЮРОКРАТИЕЙ
Подобные находки — приятная мелочь. По-настоящему же солидный улов обеспечивает более детальное знание операторов Google для веб-мастеров, самой Сети и особенностей структуры искомого. Зная детали, можно легко отфильтровать выдачу и уточнить свойства нужных файлов, чтобы в остатке получить действительно ценные данные. Забавно, что здесь на помощь приходит бюрократия. Она плодит типовые формулировки, по которым удобно искать случайно просочившиеся в Сеть секретные сведения.
Например, обязательный в канцелярии министерства обороны США штамп Distribution statement означает стандартизированные ограничения на распространение документа. Литерой A отмечаются публичные релизы, в которых нет ничего секретного; B — предназначенные только для внутреннего использования, C — строго конфиденциальные и так далее до F. Отдельно стоит литера X, которой отмечены особо ценные сведения, представляющие государственную тайну высшего уровня. Пускай такие документы ищут те, кому это положено делать по долгу службы, а мы ограничимся файлами с литерой С. Согласно директиве DoDI 5230.24, такая маркировка присваивается документам, содержащим описание критически важных технологий, попадающих под экспортный контроль. Обнаружить столь тщательно охраняемые сведения можно на сайтах в домене верхнего уровня .mil, выделенного для армии США.
“DISTRIBUTION STATEMENT C” inurl:navy.mil
Очень удобно, что в домене .mil собраны только сайты из ведомства МО США и его контрактных организаций. Поисковая выдача с ограничением по домену получается исключительно чистой, а заголовки — говорящими сами за себя. Искать подобным образом российские секреты практически бесполезно: в доменах .ru и .рф царит хаос, да и названия многих систем вооружения звучат как ботанические (ПП «Кипарис», САУ «Акация») или вовсе сказочные (ТОС «Буратино»). Внимательно изучив любой документ с сайта в домене .mil, можно увидеть и другие маркеры для уточнения поиска. Например, отсылку к экспортным ограничениям «Sec 2751», по которой также удобно искать интересную техническую информацию. Время от времени ее изымают с официальных сайтов, где она однажды засветилась, поэтому, если в поисковой выдаче не удается перейти по интересной ссылке, воспользуйся кешем Гугла (оператор cache) или сайтом Internet Archive.
ЗАБИРАЕМСЯ В ОБЛАКА
Помимо случайно рассекреченных документов правительственных ведомств, в кеше Гугла временами всплывают ссылки на личные файлы из Dropbox и других облачных сервисов, которые создают «приватные» ссылки на публично опубликованные данные. С альтернативными и самодельными сервисами еще хуже. Например, следующий запрос находит данные всех клиентов Verizon, у которых на роутере установлен и активно используется FTP-сервер.
allinurl:ftp:// verizon.net
Таких умников сейчас нашлось больше сорока тысяч, а весной 2015-го их было на порядок больше. Вместо Verizon.net можно подставить имя любого известного провайдера, и чем он будет известнее, тем крупнее может быть улов.
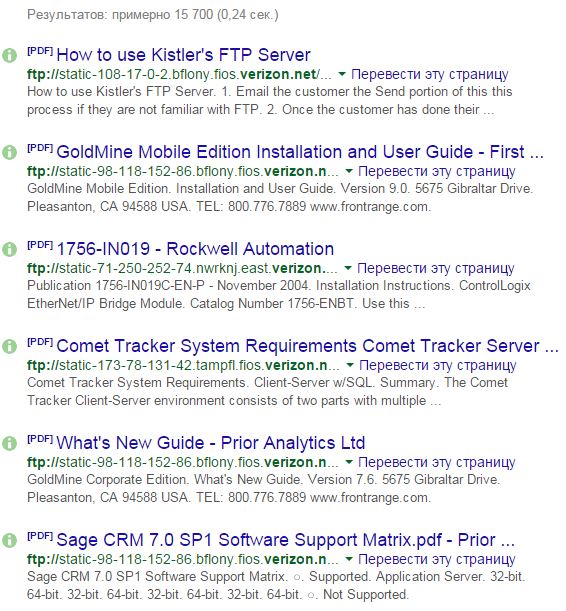
Через встроенный FTP-сервер видно файлы на подключенном к маршрутизатору внешнем накопителе. Обычно это NAS для удаленной работы, персональное облако или какая-нибудь пиринговая качалка файлов. Все содержимое таких носителей оказывается проиндексировано Google и другими поисковиками, поэтому получить доступ к хранящимся на внешних дисках файлам можно по прямой ссылке.
ПОДСМАТРИВАЕМ КОНФИГИ
До повальной миграции в облака в качестве удаленных хранилищ рулили простые FTP-серверы, в которых тоже хватало уязвимостей. Многие из них актуальны до сих пор. Например, у популярной программы WS_FTP Professional данные о конфигурации, пользовательских аккаунтах и паролях хранятся в файле ws_ftp.ini. Его просто найти и прочитать, поскольку все записи сохраняются в текстовом формате, а пароли шифруются алгоритмом Triple DES после минимальной обфускации. В большинстве версий достаточно просто отбросить первый байт.
Расшифровать такие пароли легко с помощью утилиты WS_FTP Password Decryptor или бесплатного
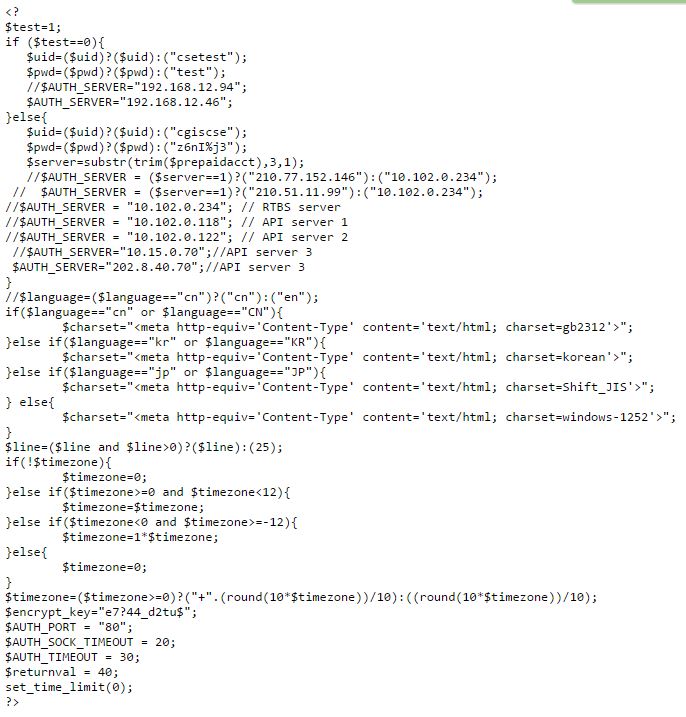
Говоря о взломе произвольного сайта, обычно подразумевают получение пароля из логов и бэкапов конфигурационных файлов CMS или приложений для электронной коммерции. Если знаешь их типовую структуру, то легко сможешь указать ключевые слова. Строки, подобные встречающимся в ws_ftp.ini, крайне распространены. Например, в Drupal и PrestaShop обязательно есть идентификатор пользователя (UID) и соответствующий ему пароль (pwd), а хранится вся информация в файлах с расширением .inc. Искать их можно следующим образом:
“pwd=” “UID=” ext:inc
РАСКРЫВАЕМ ПАРОЛИ ОТ СУБД
В конфигурационных файлах SQL-серверов имена и адреса электронной почты пользователей хранятся в открытом виде, а вместо паролей записаны их хеши MD5. Расшифровать их, строго говоря, невозможно, однако можно найти соответствие среди известных пар хеш — пароль.
До сих пор встречаются СУБД, в которых не используется даже хеширование паролей. Конфигурационные файлы любой из них можно просто посмотреть в браузере.
intext:DB_PASSWORD filetype:env
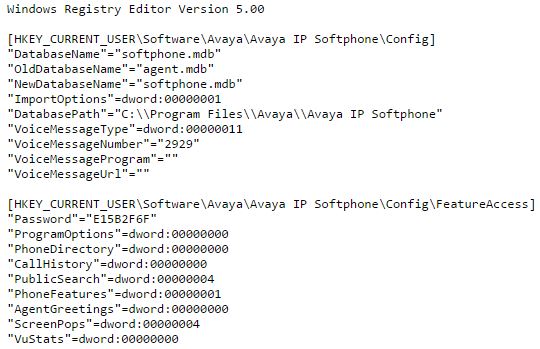
С появлением на серверах Windows место конфигурационных файлов отчасти занял реестр. Искать по его веткам можно точно таким же образом, используя reg в качестве типа файла. Например, вот так:
filetype:reg HKEY_CURRENT_USER “Password”=
НЕ ЗАБЫВАЕМ ПРО ОЧЕВИДНОЕ
Иногда добраться до закрытой информации удается с помощью случайно открытых и попавших в поле зрения Google данных. Идеальный вариант — найти список паролей в каком-нибудь распространенном формате. Хранить сведения аккаунтов в текстовом файле, документе Word или электронной таблице Excel могут только отчаянные люди, но как раз их всегда хватает.
filetype:xls inurl:password
С одной стороны, есть масса средств для предотвращения подобных инцидентов. Необходимо указывать адекватные права доступа в htaccess, патчить CMS, не использовать левые скрипты и закрывать прочие дыры. Существует также файл со списком исключений robots.txt, запрещающий поисковикам индексировать указанные в нем файлы и каталоги. С другой стороны, если структура
robots.txt на каком-то сервере отличается от стандартной, то сразу становится видно, что на нем пытаются скрыть.
Список каталогов и файлов на любом сайте предваряется стандартной надписью index of. Поскольку для служебных целей она должна встречаться в заголовке, то имеет смысл ограничить ее поиск оператором intitle. Интересные вещи находятся в каталогах /admin/, /personal/, /etc/ и даже /secret/.
СЛЕДИМ ЗА ОБНОВЛЕНИЯМИ
Дырявых систем сегодня так много, что проблема заключается уже не в том, чтобы найти одну из них, а в том, чтобы выбрать самые интересные (для изучения и повышения собственной защищенности, разумеется). Примеры поисковых запросов, раскрывающие чьи-то секреты, получили название Google dorks.
Одной из первых утилит автоматической проверки защищенности сайтов по известным запросам в Google была
Актуальность тут крайне важна: старые уязвимости закрывают очень медленно, но Google и его поисковая выдача меняются постоянно. Есть разница даже между фильтром «за последнюю секунду» (&tbs=qdr:s в конце урла запроса) и «в реальном времени» (&tbs=qdr:1).
Временной интервал даты последнего обновления файла у Google тоже указывается неявно. Через графический веб-интерфейс можно выбрать один из типовых периодов (час, день, неделя и так далее) либо задать диапазон дат, но такой способ не годится для автоматизации.
По виду адресной строки можно догадаться только о способе ограничить вывод результатов с помощью конструкции &tbs=qdr:. Буква y после нее задает лимит в один год (&tbs=qdr:y), m показывает результаты за последний месяц, w — за неделю, d — за прошедший день, h — за последний час, n — за минуту, а s — за секунду. Самые свежие результаты, только что ставшие известными Google, находится при помощи фильтра &tbs=qdr:1.
Если требуется написать хитрый скрипт, то будет полезно знать, что диапазон дат задается в Google в юлианском формате через оператор daterange. Например, вот так можно найти список документов PDF со словом confidential, загруженных c 1 января по 1 июля 2015 года. confidential filetype:pdf daterange:2457024-2457205
Диапазон указывается в формате юлианских дат без учета дробной части. Переводить их вручную с григорианского календаря неудобно. Проще воспользоваться
ТАРГЕТИРУЕМСЯ И СНОВА ФИЛЬТРУЕМ
Помимо указания дополнительных операторов в поисковом запросе их можно отправлять прямо в теле ссылки. Например, уточнению filetype:pdf соответствует конструкция as_filetype=pdf. Таким образом удобно задавать любые уточнения. Допустим, выдача результатов только из Республики Гондурас задается добавлением в поисковый URL конструкции cr=countryHN, а только из города Бобруйск — gcs=Bobruisk. В разделе для разработчиков можно найти
Средства автоматизации Google призваны облегчить жизнь, но часто добавляют проблем. Например, по IP пользователя через WHOIS определяется его город. На основании этой информации в Google не только балансируется нагрузка между серверами, но и меняются результаты поисковой выдачи. В зависимости от региона при одном и том же запросе на первую страницу попадут разные результаты, а часть из них может вовсе оказаться скрытой. Почувствовать себя космополитом и искать информацию из любой страны поможет ее двухбуквенный код после директивы gl=country. Например, код Нидерландов — NL, а Ватикану и Северной Корее в Google свой код не положен.
Часто поисковая выдача оказывается замусоренной даже после использования нескольких продвинутых фильтров. В таком случае легко уточнить запрос, добавив к нему несколько слов-исключений (перед каждым из них ставится знак минус). Например, со словом Personal часто употребляются banking, names и tutorial. Поэтому более чистые поисковые результаты покажет не
хрестоматийный пример запроса, а уточненный:
intitle:”Index of /Personal/” -names -tutorial -banking
ПРИМЕР НАПОСЛЕДОК
Искушенный хакер отличается тем, что обеспечивает себя всем необходимым самостоятельно. Например, VPN — штука удобная, но либо дорогая, либо временная и с ограничениями. Оформлять подписку для себя одного слишком накладно. Хорошо, что есть групповые подписки, а с помощью Google легко стать частью какой-нибудь группы. Для этого достаточно найти файл конфигурации Cisco VPN, у которого довольно нестандартное расширение PCF и узнаваемый путь: Program FilesCisco SystemsVPN ClientProfiles. Один запрос, и ты вливаешься, к примеру, в дружный коллектив Боннского университета.
filetype:pcf vpn OR Group
Пароли хранятся в зашифрованном виде, но Морис Массар уже написал программу для их расшифровки и предоставляет ее бесплатно через
Прокси серверы можно найти с помощью команды:
+”:8080″ +”:3128″ +”:80″ filetype:txt
[spoiler title=’литератрура’ style=’default’ collapse_link=’true’]“Mowse: Google Knowledge: Exposing Sensitive data with Google”
“Autism: Using google to hack”
“Google hacking”:
“Google: Net Hacker Tool du Jour”
“Google Hacking Mini-Guide”
“Hacking mit Google”
поисковые операторы гугла:
Теперь, мы немного изменим наш запрос, конкретизируя область поиска. Это будет выглядеть так:
Почему так изменился поиск? Все очень просто. Мы воспользовались атрибутом allintext:, который означает «все документы, содержащие данное выражение» и атрибутом site:, означающим «все сайты из данного поддомена». Таким образом мы нашли все документы из поддомена .gov.ru, содержащие слово «иванов», причем Google не надо указывать, что ведется поиск по любому написанию этого слова и в наш поиск попадут документы, содержащие слово «ивановский», «Иванов», «Ивановский», «Иванова» и многое другое. Учитывая же, что поддомен .gov.ru является собранием официальных государственных сайтов, то мы получили ссылки на все государственные сайты, содержащие документы с упоминанием этих слов в своем тексте. Если же мы Применим следующий поиск:»allintext:»Сергей Семёнович Собянин» site:.gov.ru», то мы получим все упоминания данной личности во всех возможных государственных документах, которые попали в сферу писка Google.
Какие же атрибуты поиска содержит Google? Приведем таблицу:
Поисковый запрос
Результат
nokia phone Все, что содержит nokia и phone
распродажа OR notebook Все, что содержит слово распродажа или слово notebook
«коленчатый вал» Все, что содержит словосочетание коленчатый вал
printer -cartridge Содержащее слово принтер printer без слова cartridge
Toy Story +2 Все ссылки, содержащие название мульфильма Toy Story 2
~машина Все ссылки с упоминанием слова машина или его синонимов
define:мойка Все сведения со словом мойка (в том числе и река)
Квартиры и комнаты * Москв Выдаст ссылки на квартиры и комнаты с упоминанием словаМосква
+ Сложение. На запрос 978+456, выдаст ответ 978 + 456 = 1434
– Вычитание. На запрос 978-456, выдаст 978 — 456 = 522, но, кроме этого вы получите еще и ссылки на все документы, содержащие 978-456
* Умножение. На запрос 978*456, выдаст 978 * 456 = 445968
/ Деление. На запрос 978/456, выдаст 978 / 456 = 2.14473684, но, кроме того еще и упоминание вместе этих цифр.
% of (% от) Процент. На запрос 50% of 200 hz (или 50% от 200 hz) , выдаст 50% of (200 hertz) = 100 hertz (50 % от (200 Гц) = 100 Герц)
^ Возведение в степень. На запрос 4^18, выдаст 4^18 = 68719476736
old in new (преобразование) 45 celsius in Fahrenheit (45 цельсия в фаренгейте) дает45 градусов Цельсия = 113 градусов Фаренгейта
site:(поиск только на сайте) Запрос: site:mts.ru «SMS и MMS-MAXI» выдаст все, что есть по этому тарифу во всех регионах
link:(ссылка) Этот оператор позволяет увидеть все страницы, которые ссылаются на страницу, по которой сделан запрос.
#…#(поиск в интервале) Например: жесткий диск внешний 800 руб…5000 рубвыдаст вам все варианты по цене от 800 до 5000 рублей
info: (запрос информации о странице) Пример: info:
Для просмотра ссылки необходимо нажать
Вход или Регистрация
дает ссылку на страницу информации о сети «Фейсбук»related: (похожие страницы) Пример: related:
Для просмотра ссылки необходимо нажать
Вход или Регистрация
дает ссылки на различные социальные сетиcache: (просмотр сохраненных страниц) Выдает сохраненные в кеше Google страницы сайтов
filetype:(с указанием конкретного вида типов файлов)
ext:(расширение файла) Пример: кролики filetype:ppt дает ссылку на презентации Power Point на тему «кролики»
allintitle: (ищет слова в заголовках страниц)
allinurl:отыщет заданное в теле самих ссылок
allianchor:в тексте, снабженном тегом
Для просмотра ссылки необходимо нажать
Вход или Регистрация
). Много различных гуглодорков описывают параметры, с помощью которых можно искать уязвимые приложения, критичную информацию. Гугл позволяет найти тысячи и тысячи хостов с большими дырами.Например, предыдущая задачка. Пишем простой гуглодорк «intitle:”Struts Problem Report”» и получаем «158,000 results». Конечно, гугл здесь хвастается и по факту отдельных хостов около 400, но все равно это не меняет дела — мы можем почти на 100% быть уверены, что там есть RCE, так как включен development mode.
Теперь давай посмотрим с другой стороны. Вот проводим мы пентест какого-то ресурса. Погуглодоркать нужно? Нужно. И собрать информацию нужно. Но делать это через браузер — совсем не наш метод. Нам нужна автоматизация процесса.
Варианта здесь, на самом деле, два. Первый — взять тулзу, которая эмулировала бы пользовательские запросы в гугл и парсила бы ответы. Минус здесь в том, что гугл не любит ботов и блочит их (капчу надо вводить). Но, используя большое количество прокси или отвечая на капчу «китайским методом» (то есть вручную), мы можем слить инфу с гугла. Второй — воспользоваться API гугла. Есть у него такая фича — Custom Search Engine, к которой можно получить доступ через специальный API. Здесь как раз автоматически можно получать инфу без проблем (капчи). Но есть другое ограничение — разрешено делать не более 100 запросов в день. Больше — платно (1000 запросов — 5 долларов, для примера). И вроде бы больше 100 ответов не получить. В зависимости от типа задачи (глубина или покрытие) можно выбрать один из вариантов соответственно.
Но для пентестерских задач могу порекомендовать такую тулзу, как
Для просмотра ссылки необходимо нажать
Вход или Регистрация
. Я уже частично ее описывал, в контексте поиска багов во флеше. Здесь же мы коснемся других ее возможностей — гуглохакинга.Она проста в использовании, написана на C# и работает только под win, может работать как напрямую с гуглом, так и через API. В ней нативно представлена большая база различных гуглодорков (оооочень большая), а также имеется удобная возможность сортировки и выгрузки результатов в различные форматы. То есть то, что нужно
. Итак, немного пробегусь по интерфейсу.Queries — как раз набор различных гуглодорков. Все разгруппировано и вполне понятно. Ставим галки где нужно, и он ищет по ним.
Далее Settings. Можно выбрать методы получения инфы. Если галка Disable scraper не стоит, то данные будут получаться эмуляцией гугления (не через API). Для этого метода рекомендую сразу добавить перечень proxy в соответствующей вкладке, а то слишком быстро заблочат. Если стоит галка, то используется API Googl’а. Немного подробнее об этом.
Для того чтобы получить доступ к этому функционалу, тебе нужны Google Custom Search ID и API key.
1. Заходим на
Для просмотра ссылки необходимо нажать
Вход или Регистрация
и создаем там новый поисковик. С настройками можно сильно не запариваться. В поле Sites tosearch можно добавить любое название. Это поле важно, только еслиты делаешь поиск по своему настоящему сайту (типа поиск для конкретного сайта). Для наших же целей, когда мы хотим искать много где, оно уже не важно. Потом заходим в настройки движка (edit search engine).Главное для нас здесь две вещи. Во-первых, в настройках движка установить для поля Sites to search значение Search the entire web but emphasize included sites. Так гугл будет искать по всем сайтам, а не только по нашим (потому и все равно введенное нами имя). Во-вторых, берем значение
из Search Engine ID — это, как ты понял, идентификатор нашего кастомного поисковика. То есть полдела сделано.
2. Заходим на
Для просмотра ссылки необходимо нажать
Вход или Регистрация
. Здесь нам нужно подключить сервис Custom Search API во вкладке Services соответственно. А также получить свой личный API key во вкладке API Access.
Все, теперь можно ввести оба этих значения в настройках SearchDiggity.
Следующий важный пункт — Sites, Domains, IP ranges. В нем как раз очень просто ограничить поиск для гуглодорканья. По сути, используется параметр site: от гугла. Так что можно сразу указать набор доменов, где хочешь совершать поиск, — очень удобно.
Последнее — Query appender, позволяет нам задать дополнительные строки при поиске, то есть прямо в него можно пихать гуглодорки.
Вот, в общем-то, и все. Получается очень удобно. Еще хотелось бы отметить две фичи. Первая состоит в том, что в настройках можно увеличить количество значений в ответе на запрос (Options-Settings-Google) до 100. И вторая — можно отредактировать файл в поле Default Query Definition. В нем хранится база гуглодорков. Так что можно сделать свой личный набор и оперативно использовать его впоследствии.
ФИЛЬТРУЕМ ВЫДАЧУ
По умолчанию слова и вообще любые введенные символы Google ищет по всем файлам на проиндексированных страницах. Ограничить область поиска можно по домену верхнего уровня, конкретному сайту или по месту расположения искомой последовательности в самих файлах. Для первых двух вариантов используется оператор site, после которого вводится имя домена или выбранного сайта. В третьем случае целый набор операторов позволяет искать информацию в служебных полях и метаданных. Например, allinurl отыщет заданное в теле самих ссылок, allinanchor — в тексте, снабженном тегом
1
<a name>
allintitle — в заголовках страниц, allintext — в теле страниц.
Для каждого оператора есть облегченная версия с более коротким названием (без приставки all). Разница в том, что allinurl отыщет ссылки со всеми словами, а inurl — только с первым из них. Второе и последующие слова из запроса могут встречаться на веб-страницах где угодно. Оператор inurl тоже имеет отличия от другого схожего по смыслу — site. Первый также позволяет находить любую последовательность символов в ссылке на искомый документ (например, /cgi-bin/), что широко используется для поиска компонентов с известными уязвимостями.
Попробуем на практике. Берем фильтр allintext и делаем так, чтобы запрос выдал список номеров и проверочных кодов кредиток, срок действия которых истечет только через два года (или когда их владельцам надоест кормить всех подряд).
allintext: card number expiration date /2017 cvv
intext: name adress state zip card number cvv2
Когда читаешь в новостях, что юный хакер «взломал серверы » Пентагона или NASA, украв секретные сведения, то в большинстве случаев речь идет именно о такой элементарной технике использования Google. Предположим, нас интересует список сотрудников NASA и их контактные данные. Наверняка такой перечень есть в электронном виде. Для удобства или по недосмотру он может лежать и на самом сайте организации. Логично, что в этом случае на него не будет ссылок, поскольку предназначен он для внутреннего использования. Какие слова могут быть в таком файле?
Как минимум — поле «адрес». Проверить все эти предположения проще простого.
Пишем
inurl:nasa.gov filetype:xlsx “address”
и получаем ссылки на файлы со списками сотрудников.
ПОЛЬЗУЕМСЯ БЮРОКРАТИЕЙ
Подобные находки — приятная мелочь. По-настоящему же солидный улов обеспечивает более детальное знание операторов Google для веб-мастеров, самой Сети и особенностей структуры искомого. Зная детали, можно легко отфильтровать выдачу и уточнить свойства нужных файлов, чтобы в остатке получить действительно ценные данные. Забавно, что здесь на помощь приходит бюрократия. Она плодит типовые формулировки, по которым удобно искать случайно просочившиеся в Сеть секретные сведения.
Например, обязательный в канцелярии министерства обороны США штамп Distribution statement означает стандартизированные ограничения на распространение документа. Литерой A отмечаются публичные релизы, в которых нет ничего секретного; B — предназначенные только для внутреннего использования, C — строго конфиденциальные и так далее до F. Отдельно стоит литера X, которой отмечены особо ценные сведения, представляющие государственную тайну высшего уровня. Пускай такие документы ищут те, кому это положено делать по долгу службы, а мы ограничимся файлами с литерой С. Согласно директиве DoDI 5230.24, такая маркировка присваивается документам, содержащим описание критически важных технологий, попадающих под экспортный контроль. Обнаружить столь тщательно охраняемые сведения можно на сайтах в домене верхнего уровня .mil, выделенного для армии США.
“DISTRIBUTION STATEMENT C” inurl:navy.mil
Очень удобно, что в домене .mil собраны только сайты из ведомства МО США и его контрактных организаций. Поисковая выдача с ограничением по домену получается исключительно чистой, а заголовки — говорящими сами за себя. Искать подобным образом российские секреты практически бесполезно: в доменах .ru и .рф царит хаос, да и названия многих систем вооружения звучат как ботанические (ПП «Кипарис», САУ «Акация») или вовсе сказочные (ТОС «Буратино»). Внимательно изучив любой документ с сайта в домене .mil, можно увидеть и другие маркеры для уточнения поиска. Например, отсылку к экспортным ограничениям «Sec 2751», по которой также удобно искать интересную техническую информацию. Время от времени ее изымают с официальных сайтов, где она однажды засветилась, поэтому, если в поисковой выдаче не удается перейти по интересной ссылке, воспользуйся кешем Гугла (оператор cache) или сайтом Internet Archive.
ЗАБИРАЕМСЯ В ОБЛАКА
Помимо случайно рассекреченных документов правительственных ведомств, в кеше Гугла временами всплывают ссылки на личные файлы из Dropbox и других облачных сервисов, которые создают «приватные» ссылки на публично опубликованные данные. С альтернативными и самодельными сервисами еще хуже. Например, следующий запрос находит данные всех клиентов Verizon, у которых на роутере установлен и активно используется FTP-сервер.
allinurl:ftp:// verizon.net
Таких умников сейчас нашлось больше сорока тысяч, а весной 2015-го их было на порядок больше. Вместо Verizon.net можно подставить имя любого известного провайдера, и чем он будет известнее, тем крупнее может быть улов.
Через встроенный FTP-сервер видно файлы на подключенном к маршрутизатору внешнем накопителе. Обычно это NAS для удаленной работы, персональное облако или какая-нибудь пиринговая качалка файлов. Все содержимое таких носителей оказывается проиндексировано Google и другими поисковиками, поэтому получить доступ к хранящимся на внешних дисках файлам можно по прямой ссылке.
ПОДСМАТРИВАЕМ КОНФИГИ
До повальной миграции в облака в качестве удаленных хранилищ рулили простые FTP-серверы, в которых тоже хватало уязвимостей. Многие из них актуальны до сих пор. Например, у популярной программы WS_FTP Professional данные о конфигурации, пользовательских аккаунтах и паролях хранятся в файле ws_ftp.ini. Его просто найти и прочитать, поскольку все записи сохраняются в текстовом формате, а пароли шифруются алгоритмом Triple DES после минимальной обфускации. В большинстве версий достаточно просто отбросить первый байт.
Расшифровать такие пароли легко с помощью утилиты WS_FTP Password Decryptor или бесплатного
Для просмотра ссылки необходимо нажать
Вход или Регистрация
Говоря о взломе произвольного сайта, обычно подразумевают получение пароля из логов и бэкапов конфигурационных файлов CMS или приложений для электронной коммерции. Если знаешь их типовую структуру, то легко сможешь указать ключевые слова. Строки, подобные встречающимся в ws_ftp.ini, крайне распространены. Например, в Drupal и PrestaShop обязательно есть идентификатор пользователя (UID) и соответствующий ему пароль (pwd), а хранится вся информация в файлах с расширением .inc. Искать их можно следующим образом:
“pwd=” “UID=” ext:inc
РАСКРЫВАЕМ ПАРОЛИ ОТ СУБД
В конфигурационных файлах SQL-серверов имена и адреса электронной почты пользователей хранятся в открытом виде, а вместо паролей записаны их хеши MD5. Расшифровать их, строго говоря, невозможно, однако можно найти соответствие среди известных пар хеш — пароль.
До сих пор встречаются СУБД, в которых не используется даже хеширование паролей. Конфигурационные файлы любой из них можно просто посмотреть в браузере.
intext:DB_PASSWORD filetype:env
С появлением на серверах Windows место конфигурационных файлов отчасти занял реестр. Искать по его веткам можно точно таким же образом, используя reg в качестве типа файла. Например, вот так:
filetype:reg HKEY_CURRENT_USER “Password”=
НЕ ЗАБЫВАЕМ ПРО ОЧЕВИДНОЕ
Иногда добраться до закрытой информации удается с помощью случайно открытых и попавших в поле зрения Google данных. Идеальный вариант — найти список паролей в каком-нибудь распространенном формате. Хранить сведения аккаунтов в текстовом файле, документе Word или электронной таблице Excel могут только отчаянные люди, но как раз их всегда хватает.
filetype:xls inurl:password
С одной стороны, есть масса средств для предотвращения подобных инцидентов. Необходимо указывать адекватные права доступа в htaccess, патчить CMS, не использовать левые скрипты и закрывать прочие дыры. Существует также файл со списком исключений robots.txt, запрещающий поисковикам индексировать указанные в нем файлы и каталоги. С другой стороны, если структура
robots.txt на каком-то сервере отличается от стандартной, то сразу становится видно, что на нем пытаются скрыть.
Список каталогов и файлов на любом сайте предваряется стандартной надписью index of. Поскольку для служебных целей она должна встречаться в заголовке, то имеет смысл ограничить ее поиск оператором intitle. Интересные вещи находятся в каталогах /admin/, /personal/, /etc/ и даже /secret/.
СЛЕДИМ ЗА ОБНОВЛЕНИЯМИ
Дырявых систем сегодня так много, что проблема заключается уже не в том, чтобы найти одну из них, а в том, чтобы выбрать самые интересные (для изучения и повышения собственной защищенности, разумеется). Примеры поисковых запросов, раскрывающие чьи-то секреты, получили название Google dorks.
Одной из первых утилит автоматической проверки защищенности сайтов по известным запросам в Google была
Для просмотра ссылки необходимо нажать
Вход или Регистрация
, но ее последняя версия вышла в 2009 году. Сейчас для упрощения поиска уязвимостей есть масса других средств. К примеру, SearchDiggity авторства Bishop Fox, о которой мы писали чуть выше а также пополняемые базы с
Для просмотра ссылки необходимо нажать
Вход или Регистрация
Актуальность тут крайне важна: старые уязвимости закрывают очень медленно, но Google и его поисковая выдача меняются постоянно. Есть разница даже между фильтром «за последнюю секунду» (&tbs=qdr:s в конце урла запроса) и «в реальном времени» (&tbs=qdr:1).
Временной интервал даты последнего обновления файла у Google тоже указывается неявно. Через графический веб-интерфейс можно выбрать один из типовых периодов (час, день, неделя и так далее) либо задать диапазон дат, но такой способ не годится для автоматизации.
По виду адресной строки можно догадаться только о способе ограничить вывод результатов с помощью конструкции &tbs=qdr:. Буква y после нее задает лимит в один год (&tbs=qdr:y), m показывает результаты за последний месяц, w — за неделю, d — за прошедший день, h — за последний час, n — за минуту, а s — за секунду. Самые свежие результаты, только что ставшие известными Google, находится при помощи фильтра &tbs=qdr:1.
Если требуется написать хитрый скрипт, то будет полезно знать, что диапазон дат задается в Google в юлианском формате через оператор daterange. Например, вот так можно найти список документов PDF со словом confidential, загруженных c 1 января по 1 июля 2015 года. confidential filetype:pdf daterange:2457024-2457205
Диапазон указывается в формате юлианских дат без учета дробной части. Переводить их вручную с григорианского календаря неудобно. Проще воспользоваться
Для просмотра ссылки необходимо нажать
Вход или Регистрация
ТАРГЕТИРУЕМСЯ И СНОВА ФИЛЬТРУЕМ
Помимо указания дополнительных операторов в поисковом запросе их можно отправлять прямо в теле ссылки. Например, уточнению filetype:pdf соответствует конструкция as_filetype=pdf. Таким образом удобно задавать любые уточнения. Допустим, выдача результатов только из Республики Гондурас задается добавлением в поисковый URL конструкции cr=countryHN, а только из города Бобруйск — gcs=Bobruisk. В разделе для разработчиков можно найти
Для просмотра ссылки необходимо нажать
Вход или Регистрация
Средства автоматизации Google призваны облегчить жизнь, но часто добавляют проблем. Например, по IP пользователя через WHOIS определяется его город. На основании этой информации в Google не только балансируется нагрузка между серверами, но и меняются результаты поисковой выдачи. В зависимости от региона при одном и том же запросе на первую страницу попадут разные результаты, а часть из них может вовсе оказаться скрытой. Почувствовать себя космополитом и искать информацию из любой страны поможет ее двухбуквенный код после директивы gl=country. Например, код Нидерландов — NL, а Ватикану и Северной Корее в Google свой код не положен.
Часто поисковая выдача оказывается замусоренной даже после использования нескольких продвинутых фильтров. В таком случае легко уточнить запрос, добавив к нему несколько слов-исключений (перед каждым из них ставится знак минус). Например, со словом Personal часто употребляются banking, names и tutorial. Поэтому более чистые поисковые результаты покажет не
хрестоматийный пример запроса, а уточненный:
intitle:”Index of /Personal/” -names -tutorial -banking
ПРИМЕР НАПОСЛЕДОК
Искушенный хакер отличается тем, что обеспечивает себя всем необходимым самостоятельно. Например, VPN — штука удобная, но либо дорогая, либо временная и с ограничениями. Оформлять подписку для себя одного слишком накладно. Хорошо, что есть групповые подписки, а с помощью Google легко стать частью какой-нибудь группы. Для этого достаточно найти файл конфигурации Cisco VPN, у которого довольно нестандартное расширение PCF и узнаваемый путь: Program FilesCisco SystemsVPN ClientProfiles. Один запрос, и ты вливаешься, к примеру, в дружный коллектив Боннского университета.
filetype:pcf vpn OR Group
Пароли хранятся в зашифрованном виде, но Морис Массар уже написал программу для их расшифровки и предоставляет ее бесплатно через
Для просмотра ссылки необходимо нажать
Вход или Регистрация
. При помощи Google выполняются сотни разных типов атак и тестов на проникновение. Есть множество вариантов, затрагивающих популярные программы, основные форматы баз данных, многочисленные уязвимости PHP, облаков и так далее. Если точно представлять то, что ищешь, это сильно упростит получение нужной информации (особенно той, которую не планировали делать всеобщим достоянием). Не Shodan единый питает интересными идеями, но всякая база проиндексированных сетевых ресурсов!Прокси серверы можно найти с помощью команды:
+”:8080″ +”:3128″ +”:80″ filetype:txt
[spoiler title=’литератрура’ style=’default’ collapse_link=’true’]“Mowse: Google Knowledge: Exposing Sensitive data with Google”
Для просмотра ссылки необходимо нажать
Вход или Регистрация
“Autism: Using google to hack”
Для просмотра ссылки необходимо нажать
Вход или Регистрация
“Google hacking”:
Для просмотра ссылки необходимо нажать
Вход или Регистрация
(German)“Google: Net Hacker Tool du Jour”
Для просмотра ссылки необходимо нажать
Вход или Регистрация
“Google Hacking Mini-Guide”
Для просмотра ссылки необходимо нажать
Вход или Регистрация
“Hacking mit Google”
Для просмотра ссылки необходимо нажать
Вход или Регистрация
поисковые операторы гугла:
Для просмотра ссылки необходимо нажать
Вход или Регистрация
Для просмотра ссылки необходимо нажать
Вход или Регистрация